What is Object Detection?
Object detection is a computer vision task focused on identifying the location of specific objects in visual data like images or video. With an object detection model, you can count how many instances there are of an object in an image or video, whether there is an object in a particular region of an image or video, and more.
Object detection models are used across industries for a range of use cases. For instance, the rail industry uses object detection to assure safety; manufacturers use object detection to identify defects.
Let’s take a look at an object detection model in action! Click “Webcam” below to try the interactive demo:
Drag a file here.





Tools for Building Object Detection Projects
At the heart of object detection projects is a model that can identify objects. To build a model, you need to have images representative of your use case that have labels. These labels should show the position of objects in an image with a corresponding label. Consider the image below:
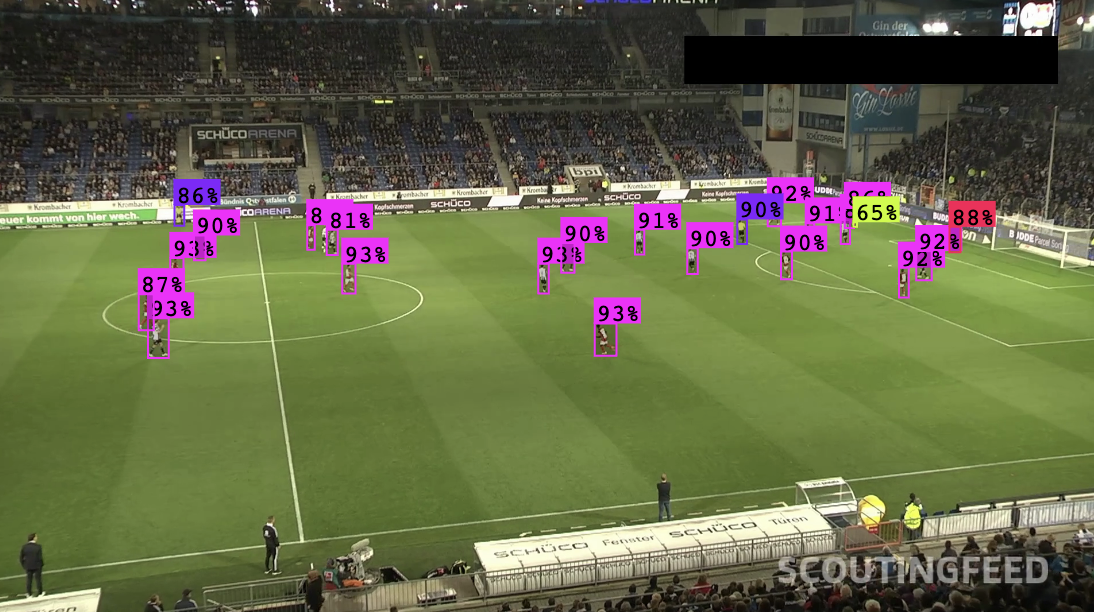
In this image, a football player is given the player label; referees and the ball are given their own labels. (These labels are not visible because they would crowd the image).
During the model training process, the model learns from the annotations. To be effective, the model needs data representative of the situation in which you plan to use your model. With enough data, a model will learn to identify the objects you want to find. Tools like Roboflow can be used to label data for training an object detection model.
With the ability to detect objects in images and videos, you can start writing logic relevant to your use case. For instance, you can track how long objects appear in an area, create logic that runs when an object is or is not found in an image, check that an image contains multiple different features, and more. A Python package like supervision can help with all of these. Supervision provides a range of general utilities for building computer vision applications.
For example, the video below was processed using supervision. Supervision processed predictions, applied them to an image, and added a counter to monitor for how long people were in each provided zone:

Deploying Object Detection Models
Once you have a model and the requisite use case, there is an important question to answer: how are you going to deploy it?
Object detection models can be powered using to a range of devices, including:
- An NVIDIA Jetson
- A Raspberry Pi
- A device with an NVIDIA GPU
- In the browser
- On an iPhone
- And more!
Solutions providers like Roboflow offer SDKs which you can use to integrate object detection models into your system across different devices. These SDKs can save a lot of time in getting your model set up and ready for use because you don't need to configure the model to operate on the hardware.
Object Detection Models
Object detection is an active area of research. There are many models available for detecting objects in images and videos. These include:
Tracking with Object Detection
You can apply object tracking algorithms such as ByteTrack to predictions from object detection models. This allows you to track individual instances of objects in an image. For example, you can track the unique players on a football field.
To learn more about tracking with object detection, check out this guide on ByteTrack tracking with YOLOv8 (object detection).
Search for an Object Detection Model
Use the search engine below to explore object detection models across a range of use cases. This search engine is powered by Roboflow Universe, a community of over 200,000 computer vision datasets and 50,000 trained models.
Selected Object Detection Models

Plane Detection
Count airplanes photographed using aerial imagery techniques.

Warehouse Item Detection
Detect forklifts, pallets, and small load carriers, among other items you would find in a warehouse environment.

License Plate Detection
Identify license plates in an image.
Object Detection vs. Classification
Object detection models tell you where an object is in an image, and are capable of identifying multiple different types of objects in an image. Classification models, on the other hand, assign one or more labels that represent the contents in an image. Classification models cannot help if you want to know where something is in an image.
Classification models can be part of two-stage detection processes. These are applications that use classification to determine if an image is relevant to a particular need, then detection to identify the location of objects in images. This is a useful pattern because classification can run quicker than object detection, allowing you to save on running object detection on images that are not relevant.
For example, you could build an application that identifies if an image is during sunlight hours or dark hours, and then use object detection to count the number of vehicles with headlights on or headlights off.
Object Detection vs. Segmentation
Object detection models return coordinates for a box in which the model thinks an object of interest can be found. For most use cases, this level of precision is enough. However, sometimes you need more precision. That’s where segmentation comes in. Segmentation models isolate, to the pixel level, the location of an image.
Segmentation models return “masks” which map to each pixel in an image. For instance, you could use segmentation to identify exactly where a crack is in a piece of concrete, whereas object detection could only tell you in what area the crack appears.
You can also use segmentation to measure the size of objects in an image.
Annotating images for use with segmentation models takes longer because you need to be more precise in your annotations; you need to annotate with polygons that wrap as close around an image as possible. Furthermore, segmentation models typically take longer to run than object detection.
Object Detection Learning Resources
Ready to start training your first object detection model? The resources curated below will help guide you through understanding object detection in greater depth and building models.

Object Detection Models
Explore over 15 different models used in object detection and find links to detailed guides on how to use them.

How to Train a YOLOv8 Model
This guide shows how to train an Ultralytics YOLOv8 computer vision model on a custom dataset.

supervision
supervision provides a range of utilities for working with computer vision models, from counting items in a zone to model evaluation.